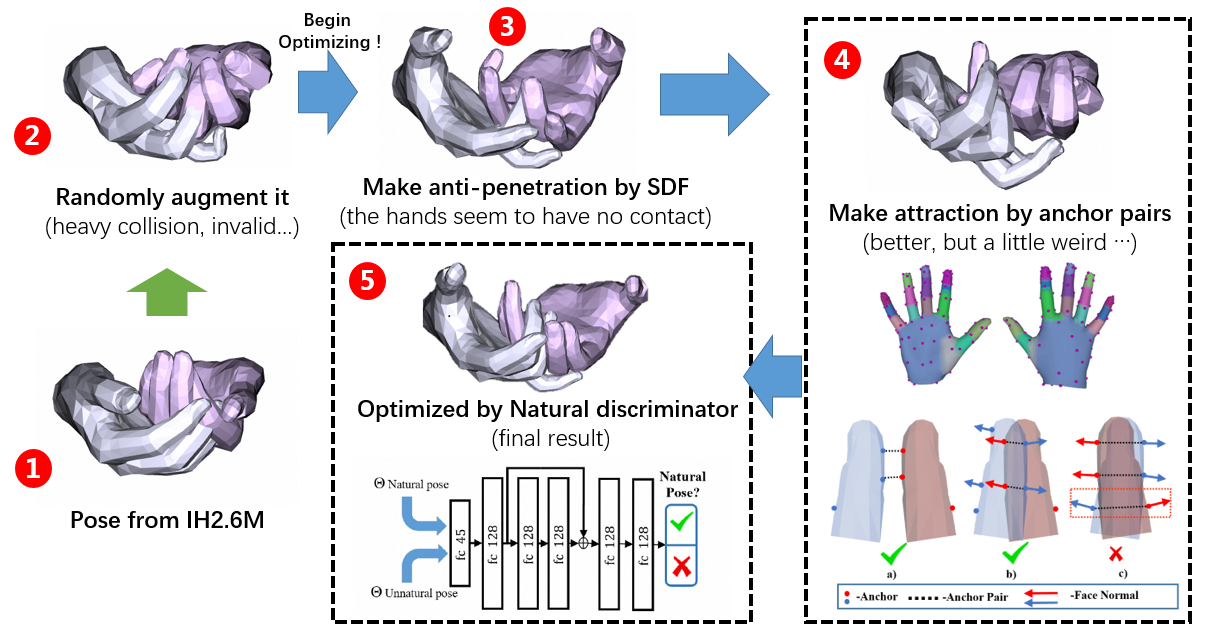
Pose Optimization
In order to make the generated pose valid and natural, we follow the steps below to generate plausible hand poses.
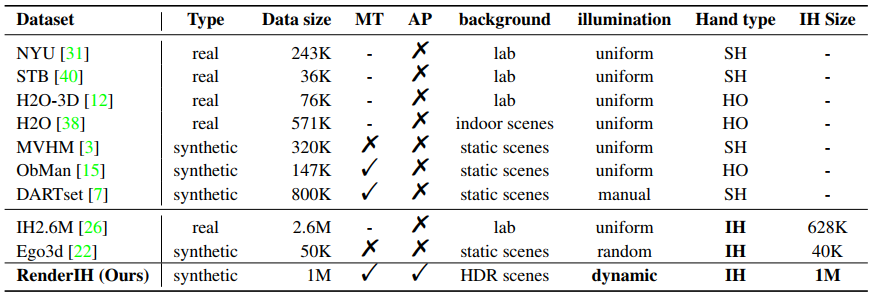
The current interacting hand (IH) datasets are relatively simplistic in terms of background and texture, with hand joints being annotated by a machine annotator, which may result in inaccuracies, and the diversity of pose distribution is limited. However, the variability of background, pose distribution, and texture can greatly influence the generalization ability.
Therefore, we present a large-scale synthetic dataset --RenderIH-- for interacting hands with accurate and diverse pose annotations. The dataset contains 1M photo-realistic images with varied backgrounds, perspectives, and hand textures. To generate natural and diverse interacting poses, we propose a new pose optimization algorithm.
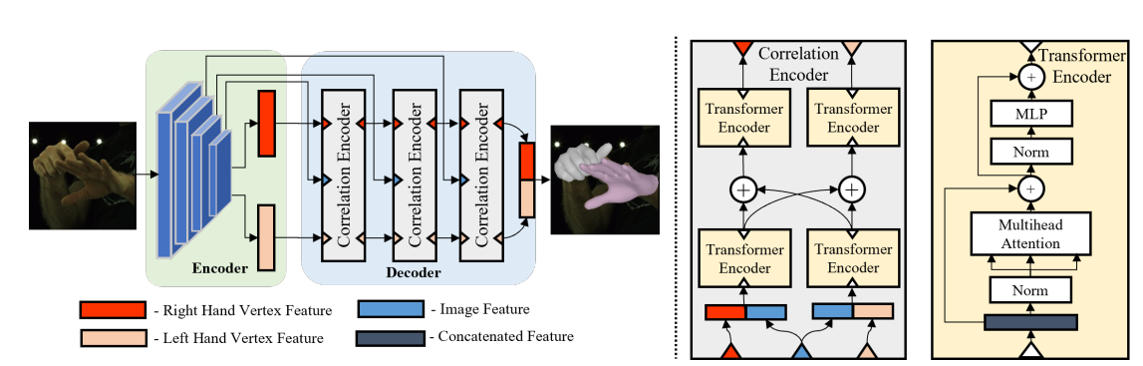
Additionally, for better pose estimation accuracy, we introduce a transformer-based pose estimation network, TransHand, to leverage the correlation between interacting hands and verify the effectiveness of RenderIH in improving results. Our dataset is model-agnostic and can improve more accuracy of any hand pose estimation method in comparison to other real or synthetic datasets. Experiments have shown that pretraining on our synthetic data can significantly decrease the error from 6.76mm to 5.79mm, and our Transhand surpasses contemporary methods.
In order to make the generated pose valid and natural, we follow the steps below to generate plausible hand poses.
In order to make the generated hand vivid, we use different hand texture and background for generation.

We introduce a transformer-based pose estimation network called TransHand which usees the global features extracted by the encoder to predict the left-hand features and right-hand features.
When pretraining on RenderIH and finetuning on the IH2.6M data, our method can further reduce the MPJPE by about 1mm. Better hand-hand contact (CDev) and better relative root translation (MRRPE) can be observed in this table. (* means official code reproduction, # means RenderIH pretraining)
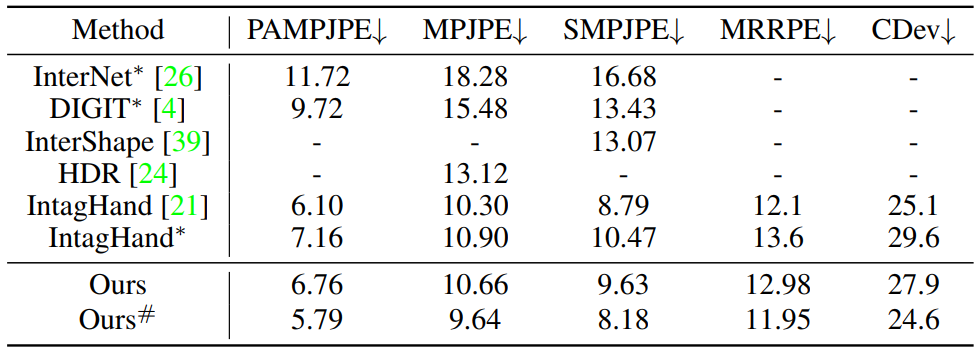
When wrist joint is used as root for comparison, comparison of training with or without our dataset and test on IH2.6M dataset.

@InProceedings{Li_2023_ICCV,
author = {Li, Lijun and Tian, Linrui and Zhang, Xindi and Wang, Qi and Zhang, Bang and Bo, Liefeng and Liu, Mengyuan and Chen, Chen},
title = {RenderIH: A Large-Scale Synthetic Dataset for 3D Interacting Hand Pose Estimation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {20395-20405}
}